Purdue DataFest 2017: Lessons in Data Parsing
DataFest
Every year the American Statistical Association hosts the DataFest competition. The main goal of the competition is to spend a few days analyzing a new dataset and presenting actionable insights in teams. Every year a different dataset is provided by a different company, who describe the dataset and ask some questions that they are interested in learning themselves. This year’s data came from Expedia’s hotel lineup.
Data
We were given two data files. One included the search queries of users with the hotel parameters they searched, how many hotels they looked at, whether they booked a hotel, and other metadata. The second file had information regarding the destinations that were being searched in the first file. This file had numerous scores of a set of popular activities in vacations spots for all the distinct vacations destinations in the first file.
Parsing
One of our team’s goals was to try to predict bookings given the data, which I worked on. We had some success with this in previous DataFest 2016, but we didn’t know if it was even possible given the data provided. Regardless I had to parse the data in a way that could be used by predictive models.
I first started by joining the two datasets together so that each entry for the destination in the first file would also have specific destination information from the second file. For this prediction task we wanted to start off with the richest dataset possible and see which attributes I needed later.
Given this larger set of data, I had to parse it into a numeric representation. With Pandas I was able to split attributes such as date and time with ease, and categorical variables into one hot encoded representations. One debate was whether or not to encode large categorical attributes, such as city where there are lot of possible values. Taking the city example, I didn’t encode it as the team debated to use popular activities scores to help distinguish the destinations.
Testing with a few thousand examples we were able to generate our new parsed data set by splitting, encoding, and normalizing attributes relatively fast. We wanted to look at how booking versus not booking results looked like with the features that we generated. When we reduced the data to 3 dimensions we saw two clusters of data, but they didn’t separate the booking status.
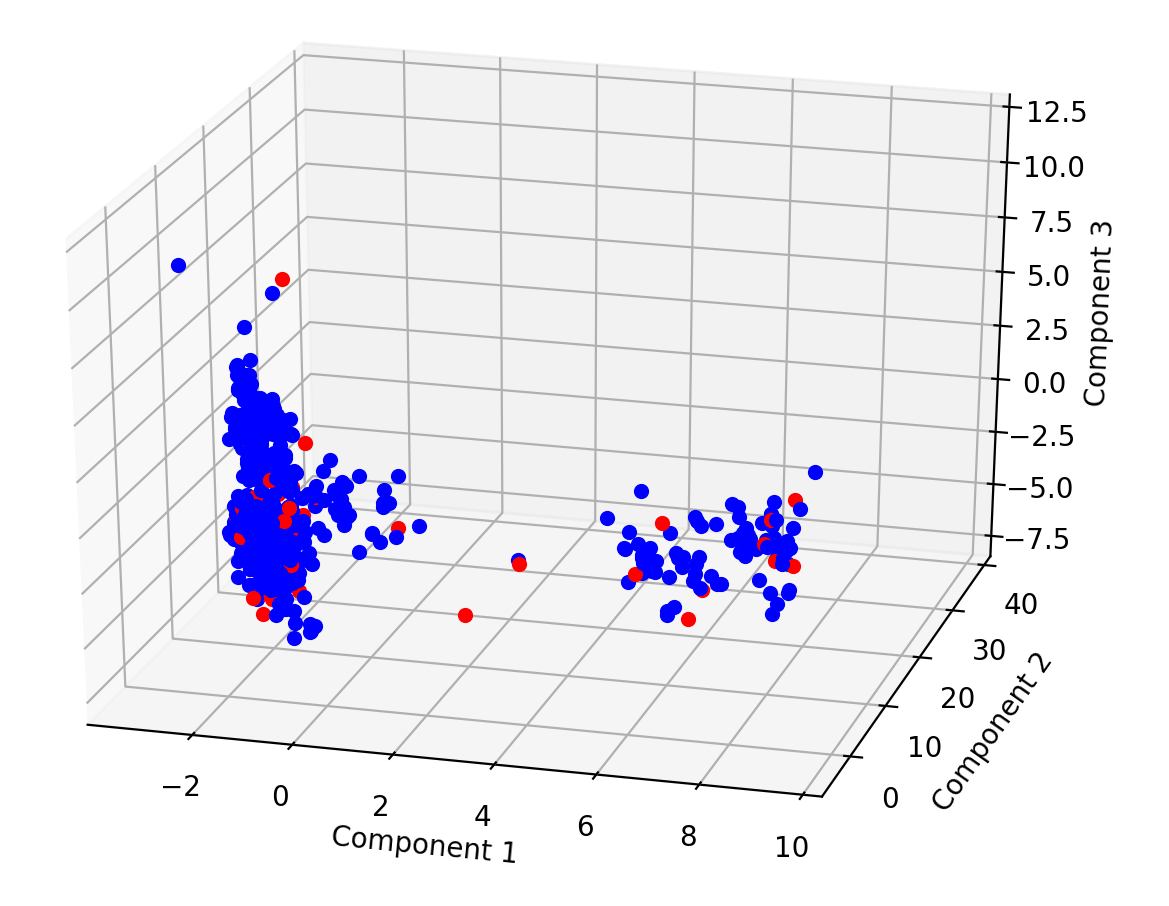
Some of these points could have been outliers, since we only used a small portion of the data, so I decided to take the time to parse all 10 million examples for the same test and to use later for prediction.
Issues came when parsing the data by attribute as some attributes were corrupted or invalid (ie the year 20015 will throw off your Pandas Datetime parser). Individually this is fine, as we can skip those examples, but with the splits and encodings, having issues with multiple attributes means that we have to remove the features that we have already added to the parsed dataset for the example that was corrupted (I didn’t want to go to much into imputation given the time I had to work on this).
This process of removing the corrupted example by index was getting complicated and had a higher chance contaminating the data if features for different instances got mixed. I then decided to parse each instance individually. Compared to performing splitting, encoding, and normalizing by each attribute at a time, performing it on each row is a lot less efficient, as I need to switch between those parsing methods based on what attribute I was parsing at the time, versus a batch operation on a column is much faster with Pandas and Numpy.
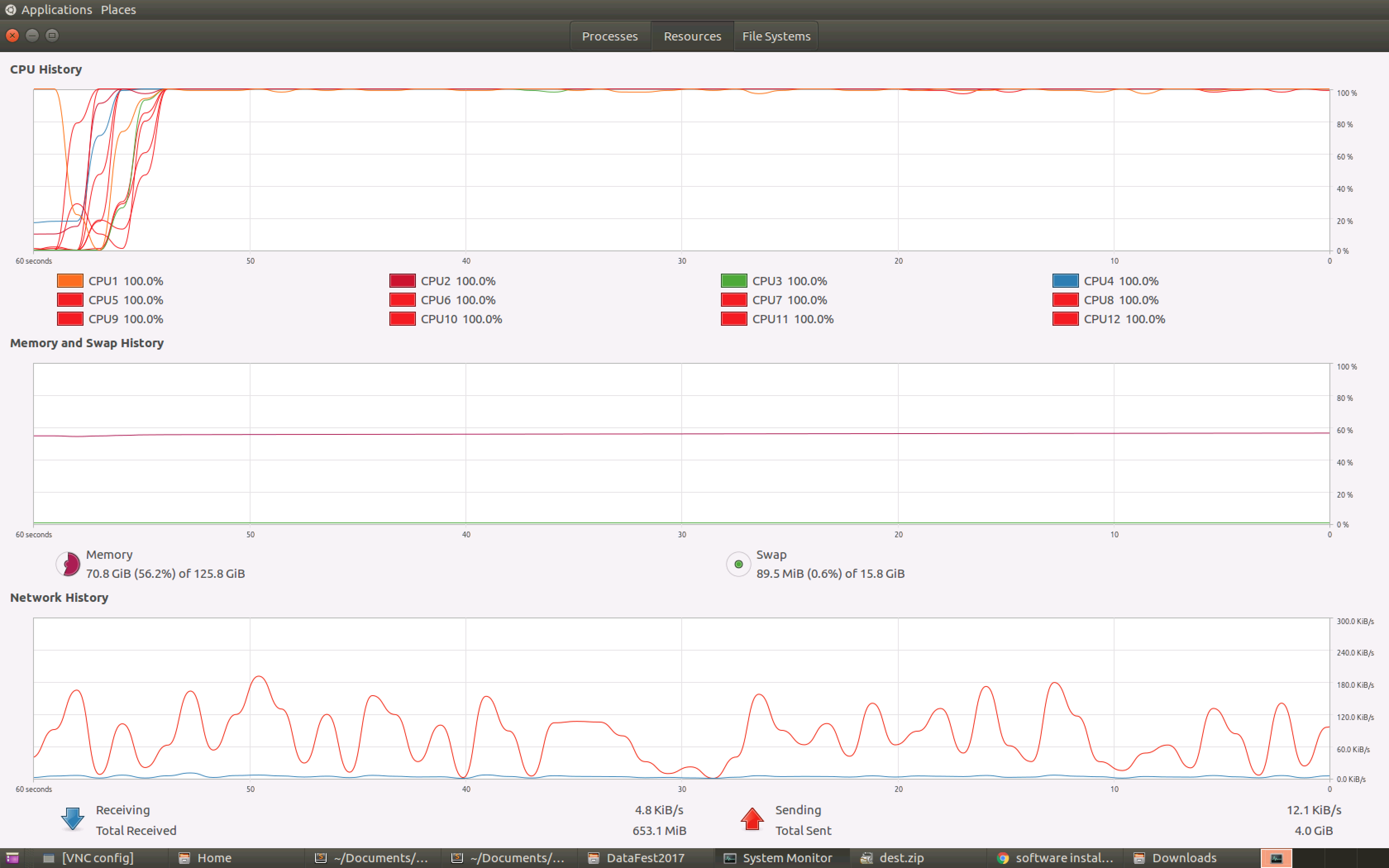
In this space, using ThreadPool versus Processes made all the difference. Threading the parsing process using Python’s ThreadPool permuting in the same memory space only was able to utilize 1/2 of my machine’s cores at around 20% efficiency. Essentially having no threading for tasks like these is better.
pool = ThreadPool(multiprocessing.cpu_count())
chunkSize = int(math.ceil(len(data) / float(threads)))
output = pool.map(generateDF, [data[chunkSize * i:chunkSize * (i + 1)] for i in range(0,math.ceil(len(data)/len(data)))])
pool.close()
pool.join()
Utilizing some basic processing code we were able to isolate each of the parsing problems and combine the results form each process:
parsedDFs = Queue()
threads = multiprocessing.cpu_count()
chunkSize = int(math.ceil(len(data) / float(threads)))
processes = []
for i in range(threads):
p = Process(target=generateDF,args=(data[chunkSize * i:chunkSize * (i + 1)], parsedDFs))
processes.append(p)
p.start()
returnDF = []
for i in range(threads):
returnDF.extend(parsedDFs.get())
for process in processes:
process.join()
The performance was improved by a large amount, as I was able to utilize all our computing power. Neat!
The Takeaway
When I fully parsed the data, I had little time to actually build predictive models. A last effort led to running the data through various models from Scikit-learn, which performed sub-optimally. Looking at the same reduced graph, it showed that booking couldn’t be easily separated when looking at a larger sample size.
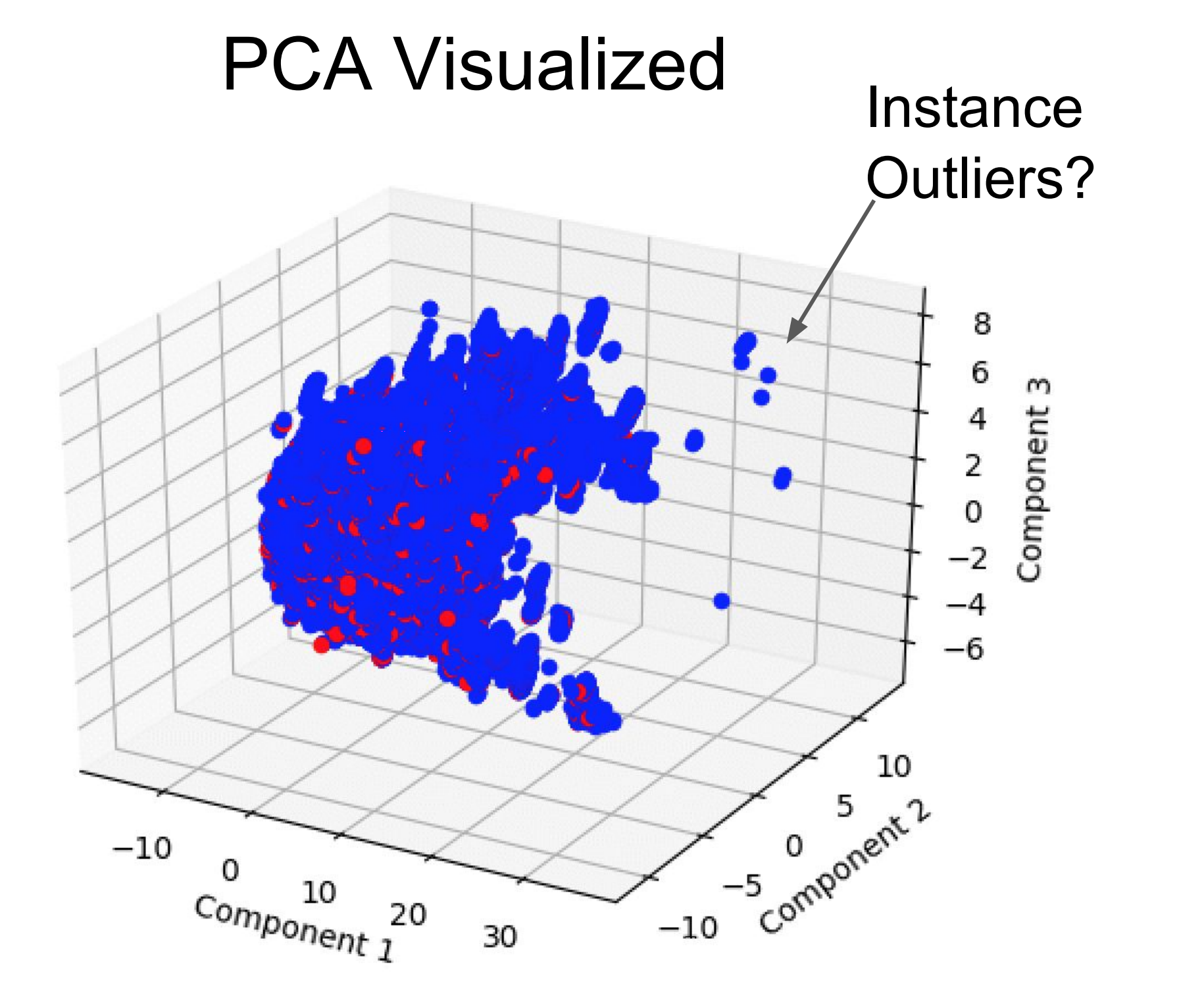
If I spent more time feature engineering and used under and oversampling techniques, the results could have been more significant, as other DataFest teams were able to make more useful predictive models for booking using new features and ensemble techniques.
Regarding parsing, next time I spend more time parsing code by attribute and dealing with bad values accordingly. The time it takes to parse by attribute instead of by individual instance would have saved a lot of preprocessing time to generate the data. An overview of our entire team’s presentation can be viewed here.