Connecting an eGPU to a MacBook For Deep Learning
GPUs in Deep Learning
There is a large market in businesses today built on the advancements in machine learning and artificial intelligence. With the developments in the algorithms and models that drive these concepts, a parallel use and development of the hardware to run and train these models is ongoing.
Researchers and those working on deep learning side of ML and big data related competitions often invest in graphics processing units to accelerate their work flow. These GPUs are built to handle parallel computation of tensors, or high dimensional matrices. When working on research utilizing these deep learning models, I decided to invest in one.
Obtaining a Setup
When choosing a GPU, there are many factors for which one works best for you, and are covered very well by Tim Dettmers. I eventually chose a Nvidia Titan X, which had more than enough memory and bandwidth to run today’s deep learning models.
The second task was deciding how to set it up. Since I commute often, I didn’t want to invest in building a full computer setup. So the only other possibility was to find a way to hook up by GPU to the MacBook that I own externally. In this market there are not too many options, with the most common solution being a PCIe to Thunderbolt board.
There are a few companies that manufacture these solutions intended to host typical PCIe cards such as RAID cards or video capture cards, but don’t supply enough power to run a GPU by default. Most people are able to take apart these platforms to add their own power supply and PCIe riser to overcome the power limit. Since I didn’t want to spend too much time tinkering with the hardware, I opted for a pre-built solution by Bizon.


Compatibility
When I received my PCIe box, I was concerned that It would take a while to configure OSX with driver modifications. I also was questioning if it would work with Theano, a tensor python library I am writing my code with.
In terms of drivers, there setup was much easier than expected, as goalque already wrote a script that detected the card, pulled the drivers from Nvidia and changed the appropriate IOPCI tunnelling files. When I rebooted the card was recognized!
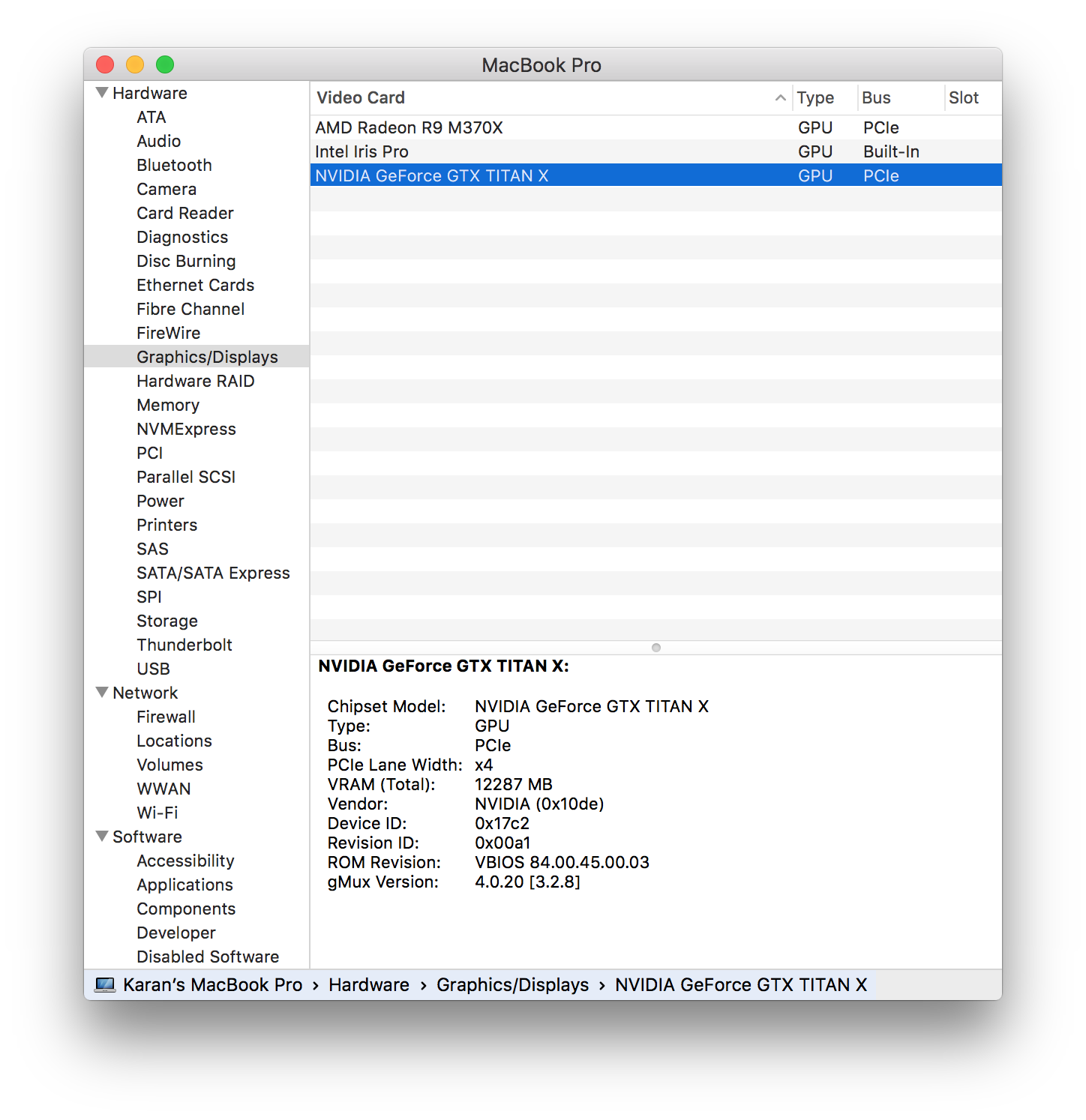
The reason why most people use Nvidia cards to run these sort of computations is due to CUDA. CUDA, proprietary to Nvidia, allows users to directly run code directly on the GPU. Many languages and packages targeted towards deep learning have integrated their libraries with CUDA to let users run demanding code on GPUs in the comfort of high level languages such as Python or Lua. Nvidia’s cuDNN also optimizes many of the operations that occur during machine learning and have been utilized by libraries, such as Theano, as well. I then continued by installed CUDA (I recommend using the full installation for those who just started) and cuDNN (you need to make a free developer account).
Performance Restrictions
While having a portable setup is nice, I knew that there were going to be some restrictions. Since the card was running off of a thunderbolt connections, there are possibilities for bottlenecks, as Thunderbolt 2 maxes out at 2.5 GB/s. From the system configuration above, we actually see that the card is running on PCIe at x4. Since thunderbolt 2 only supports PCIe 2 would usually be able to transfer at 2 GB/s, which for better or for worse within our theoretical bandwidth (You can argue that once you load in the data it wouldn’t matter much after that point).
Video cards get hot, especially with the stock cooler that comes with the Titan X. Usually decent radiators and cooling systems inside PCs can mitigate this problem. Since my box doesn’t have any additional cooling, If I run the card for extended periods of time, which I hope to when training my models, I’m going to expect some extra thermal throttling, and thus a reduction in clock speeds.
Performance Tests
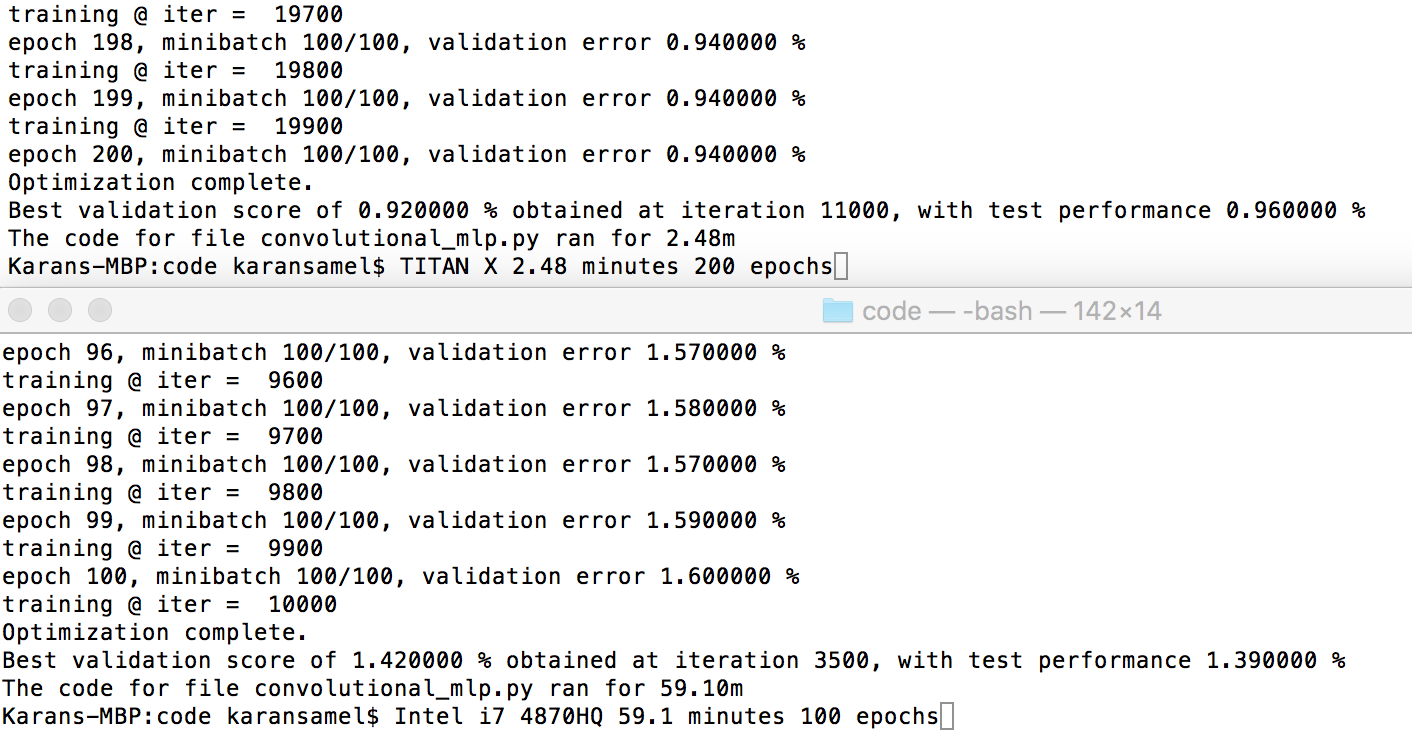
Regardless of the potential speed and thermal issues, I was quite pleased by how the card performed. Running convolutional_mlp, I was able to get a 45-50x speedup.
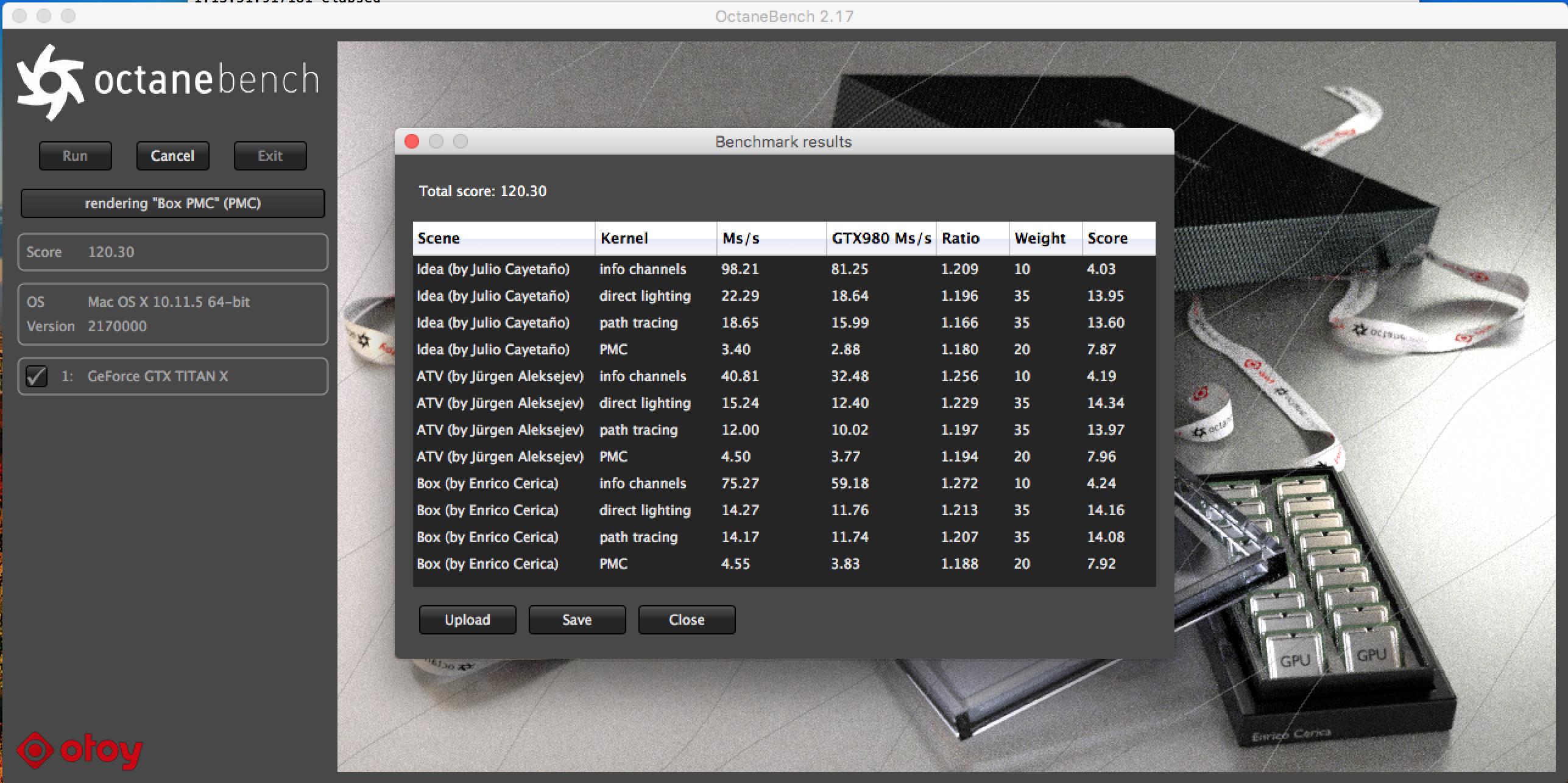
Running some synthetic benchmarks (I might test and post other ones in the future), I got about the same score as a Titan X would in a rig (could be in the margin of error due to different CPUs, PCIe configs, RAM, etc.).

Finally when testing out my personal code, after adjusting some of the CUDA and Theano global variables, I got it to work smoothly. From the different models I was testing, MLP, CNN, RNN, I was able to get around a 23-30x speedup from the i7-4870HQ in my MacBook to the Titan X.
So far these test have been relatively superficial, so I’m going to run some larger models with larger batch data sizes that I’m working with and maybe I can find other positive and negative aspects as I go along. I want to eventually also test this setup against other common large models with Alexnet and Google LeNet to see how these variables affect model training performance.